Introduction
In this tutorial I want to show you guys how to go from two distinct images to a single image that is the result of the two images stitched together. This is a very useful technique in computer vision and it is used in many applications such as panorama stitching, object detection and many others.
Starting images:


The final result:

The code
Feature extraction
| |
SIFT algorithm is going to be used for keypoint extraction and feature description. The algorithm is going to be initialized as follows:
| |
Next two images are going to be used for the demonstration of the algorithm. IMPORTANT: the images should be ordered from the left to the right.
| |
| |
With the images open now the SIFT algorithm can be run on each of them. The keypoints and descriptors are going to be extracted and stored in the variables kp1, des1, kp2, des2.
Following are the two images with the descriptors visualized. It can be noted that some of the descriptors are similar and in similar positions in both images.
| |
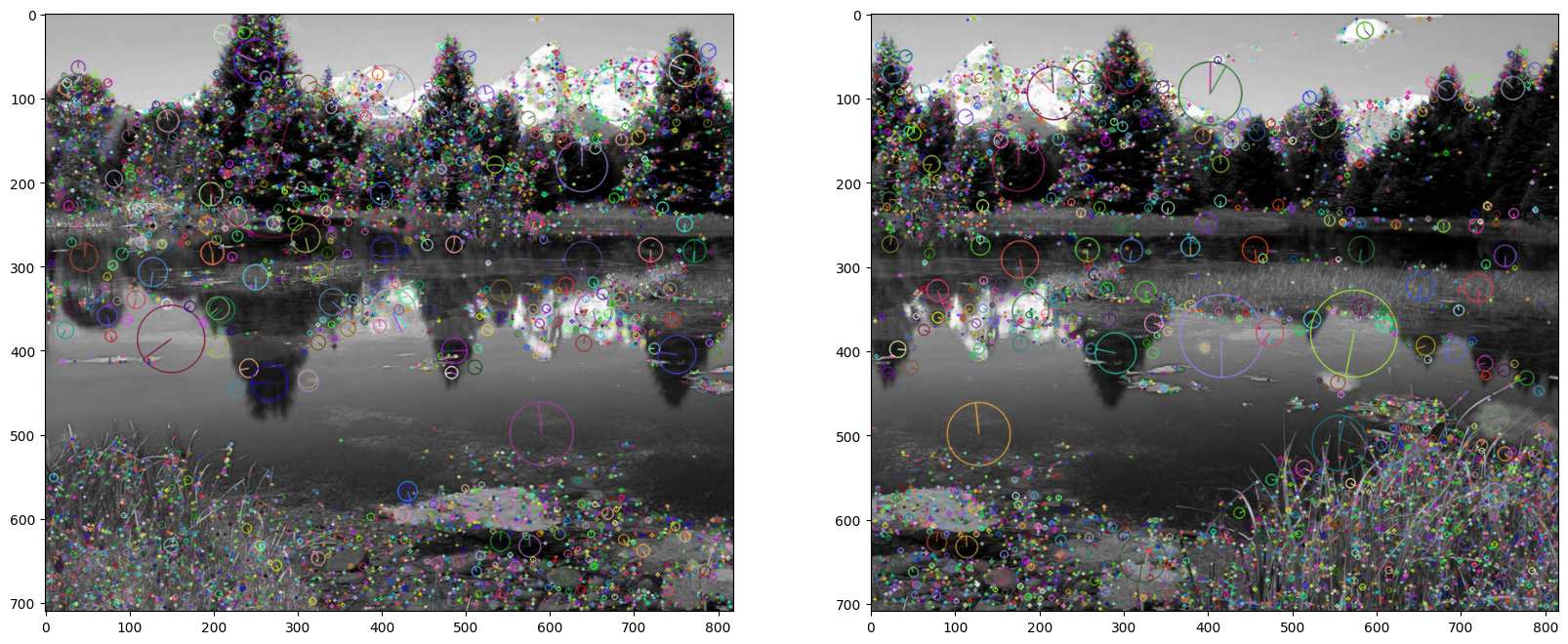
Feature matching
Now that the points have been computed, the next step is to match the points. This is done by using the FLANN algorithm. This Algorithm is faster than the brute force approach and gives the same accuracy. It involves trees and it is a best fit when the number of matches is high, which is exactly our case.
After matching the points a further refinement is done with the ratio test. This test is used to filter out the points that are not similar enough. The test is done by comparing the distance of the closest point to the distance of the second closest point. If the ratio is less than a certain threshold, the point is considered a good match.
The result is shown in the figure below. The matches are visualized with lines connecting the points. It can be seen that the matches are not perfect, this is why we are going to refine them in the next step.
| |
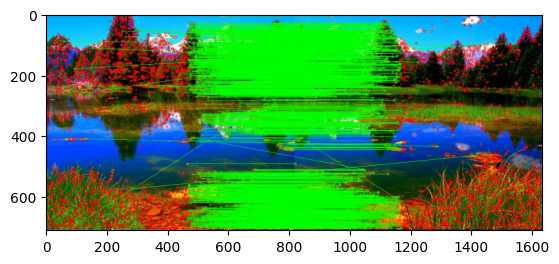
(<matplotlib.image.AxesImage at 0x1571581c0>, None)
From the previous image it can be seen that some green lines do not match corresponding keypoints. This is why we are going to use the RANSAC algorithm to further refine the matches. The RANSAC algorithm is going to be used to find the best transformation between the two images. The transformation is going to be used to warp the second image to the first one.
RANSAC - Matching refinement
| |
In particular the RANSAC algorithm works as follows:
- Randomly select n points from the matches
- Compute the transformation
- Count the number of inliers, that is, if we take this transformation as the correct one, how many points are close to the transformed points (we need to consider all the points and not only the n points we used to compute the transformation)
- Repeat the process for a number of iterations to find the best combination of points that minimizes the transformation error
Once the iteration is finished we can consider with a high degree of confidence that the current transformation is the closest to the real one. The transformation is then used to warp the second image to the first one.
| |
All the code you see above seems gibberish, but is actually the implementation of the bullet points that I described earlier.
In particular:
| |
is responsible for transforming the source points to the destination points given any homgraphy matrix.
| |
Is responsible for finding the homography matrix given the source and destination points.
| |
Is responsible to run the RANSAC algorithm and find the best homography matrix. It calls many times both the previous functions to find the best homography matrix.
Next we can compute the best homography matrix and warp the second image to the first one. We also get the indices of the points that are inliers and we can visualize them. We remove all points that are not the best fits by applying the mask to the matches.
| |
We can visualize our predicted homography matrix and the refined matches. The result is shown in the figure below. It can be seen that the matches are now much better and the green lines are now connecting the correct keypoints.
| |
array([[ 9.99962996e-01, 1.45216964e-05, -4.62984718e+02],
[-1.84901804e-05, 1.00002364e+00, 8.65968096e-03],
[-1.51650074e-08, 4.51000004e-08, 1.00000000e+00]])
| |
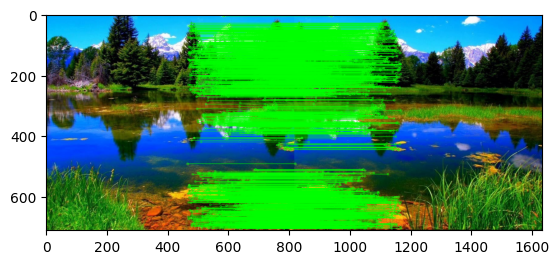
(<matplotlib.image.AxesImage at 0x16c2ca8c0>, None)
Stitching the two images
The last part of the code involves creating a new frame for the images based on their projected new positions. The new frame is going to be the calculated from the new coordinates of the second image projected by the homography matrix and the original frame of the first image. The new frame is going to be the maximum of the two frames.
Then the function $\text{cv2.warpPerspective}$ is going to be used to warp the second image to the first one. The result is shown in the figure below. It can be seen that the second image is now warped to the first one and the two images are now aligned.
| |
Other examples
For my project I had to use different images to test the algorithm. The results are shown in the figures below. It can be seen that the algorithm works well and the two images are stitched together.


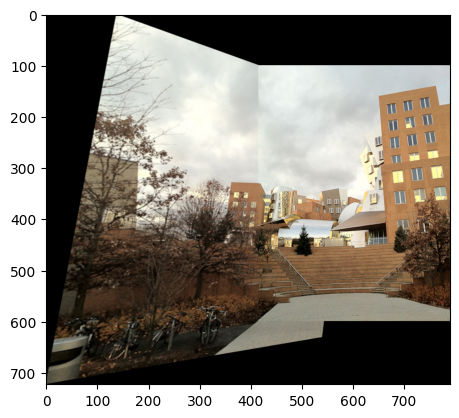





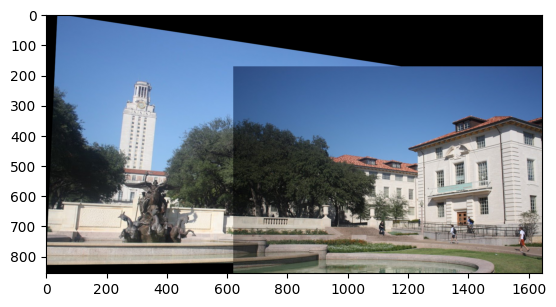
Note: Especially in the last one it can be noted that the images have different colors. In the next section we are going to see how to fix this issue.
Photometric correction
Conclusion
As promised the two images have been stitched together and the result is shown in the figure above. The process is quite simple and it is based on the extraction of keypoints and descriptors, the matching of the keypoints and the refinement of the matches with the RANSAC algorithm. The final result is a single image that is the result of the two images stitched together.